
斯道德机械2026秋招:无锡制造业外贸与研发岗解读
斯道德机械2026秋招启动,岗位覆盖研发、国贸及小语种。本文解析其在无锡的产业链优势、人才公寓等福利,对比外贸与研发岗差异,助应届生判断是否值得投递。

本模板专为数据开发工程师精心设计,突出大数据处理、ETL、数据仓库构建及编程技能。简洁专业的设计风格,助您清晰展示技术实力与项目经验,快速吸引招聘官目光,轻松应对互联网、AI、金融等行业的数据开发职位挑战。
本模板特别适合数据开发工程师岗位的求职者使用,具备不限工作经验的专业人士, 通过技术类风格的设计,帮助您在互联网 行业中脱颖而出,展现专业形象和核心竞争力。
使用模版创建简历
本模板专为拥有3年工作经验的程序员,尤其是前端开发者设计,即使非名校背景,也能通过极客风格的布局和清晰的结构,突出技术实力和项目经验。模板注重代码感和专业性,帮助候选人快速吸引招聘官眼球,提升面试机会。

这款商务风格产品经理简历模板,专为追求专业与效率的产品经理设计。版面布局严谨,信息呈现清晰,突出项目经验和数据成果,帮助您在众多候选人中展现出卓越的产品规划与执行能力。适用于各行业产品经理职位,尤其适合有一定工作经验的求职者。

本数据分析总监简历模板专为资深数据分析专家和管理人员设计,强调数据战略规划、团队领导与业务增长能力。模板布局清晰,突出关键成就和量化成果,助力您在竞争激烈的高级职位招聘中脱颖而出,展现作为Director of Data Analytics的卓越领导力与数据洞察力。

本简历模板专为iOS和Android客户端开发工程师设计,强调技术深度与项目经验。模板结构清晰,突出开发技能、项目亮点和技术栈,帮助求职者快速吸引招聘官注意,尤其适合有iOS或Android双平台开发经验的工程师。简洁专业的版面布局,确保信息传达高效。
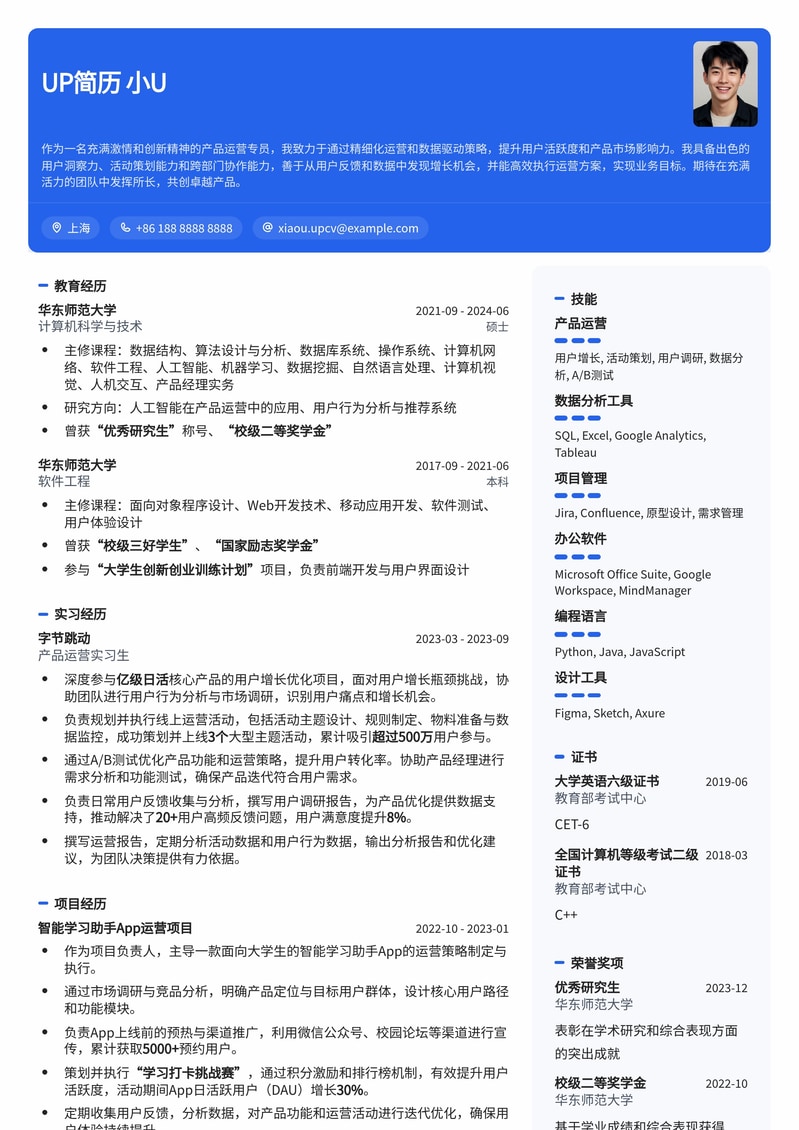
专为985高校毕业生及校友量身定制的产品运营专员简历模板。此模板突出985背景优势,强化项目经验和数据分析能力,助您在激烈的互联网产品运营岗位竞争中脱颖而出,直达心仪Offer。

本模板专为数字IC设计工程师量身打造,突出您的芯片设计、验证、综合与布局布线等核心技能。结构清晰,重点突出项目经验与技术成果,助您在众多求职者中脱颖而出,快速获得心仪的数字IC设计职位面试机会。

本简历模板专为推荐算法工程师量身定制,突出项目经验、模型优化能力和数据分析洞察力。通过清晰的结构和重点内容展示,帮助求职者在众多简历中脱颖而出,直击HR和面试官的关注点,提高面试邀约率。适用于1-5年推荐算法经验的求职者。

本模板专为志向京东后端开发岗位的应届毕业生精心打造。内容结构清晰,重点突出项目经验、技术栈与实习经历,完美契合京东等一线互联网公司招聘偏好。通过此模板,应届生能有效展示其扎实的技术基础、解决问题能力和学习潜力,助您在众多求职者中脱颖而出,直达心仪Offer。
专业指导,提升简历质量
斯道德机械2026秋招启动,岗位覆盖研发、国贸及小语种。本文解析其在无锡的产业链优势、人才公寓等福利,对比外贸与研发岗差异,助应届生判断是否值得投递。
解读2026年中国网络安全审查认证和市场监管大数据中心春招。分析单位背景、北京户口解决概率及不限专业岗位真实性,帮助应届生判断是否值得投递。
华金证券2026秋招启动,“华金新锐”管培生项目面向硕士应届生。本文深度拆解产融服务、金融数智、风控合规及财富管理四大赛道,分析珠海国资背景下的稳定性与薪资竞争力,助你判断投递价值与备考策略。
易思维2026暑期实习招聘解读。作为工业视觉检测领域的“专精特新”企业,易思维为汽车与半导体行业提供核心测量方案。本文分析现场技术支持等核心岗位需求,指出该实习对工科生积累软硬结合工程经验的独特价值,助你判断是否值得投递。
中国水产科学研究院2026第三批春招启动,学历专业限制放宽。本文解读国家级科研“铁饭碗”的真实待遇、哈尔滨岗位工作内容及适合人群,帮你判断是否适合放弃企业KPI选择纯粹科研环境。
OPPO 2026 秋招正式开启,覆盖全国 8 大核心城市。本文深度解析其行业地位、技术岗与非技术岗的投递难度差异,以及应届生在 AI 转型期的发展机会与加班现状,助你快速判断是否值得投递。
资深数据开发工程师,拥有<strong>5年</strong>以上数据平台构建与优化经验,精通大数据技术栈(Hadoop、Spark、Kafka),具备扎实的数仓建模、ETL开发及性能调优能力。<strong>擅长将复杂业务需求转化为高效数据解决方案</strong>,致力于通过数据驱动业务增长与决策优化,在多个项目中实现<strong>数据处理效率提升30%</strong>,为业务增长提供有力支持。
字节跳动
腾讯科技
个人项目
个人项目
硕士 · 计算机科学与技术
学士 · 软件工程
Hadoop · Spark · Flink · Kafka · Hive · HBase · ClickHouse
Java · Scala · Python · SQL
数仓建模 · ETL开发 · 数据治理 · 数据质量
AWS · 阿里云 · 容器化 (Docker, Kubernetes)
Git · Jenkins · Airflow · Prometheus · Grafana
Cloudera
证明在大数据分析和Hadoop生态系统中的专业能力。
Ververica
验证在Apache Flink流处理框架上的开发与优化技能。
选择专业模板,AI智能填写,3分钟完成简历制作